


党的二十届四中全会通过的《中共中央关于制定国民经济和社会发展第十五个五年规划的建议》(以下简称《建议》),为未来五年中国经济社会发展谋篇布局。其中第四部分“加快高水平科技自立自强,引领发展新质生产力”讲科技创新,这个部分中单列了一条“推动科技创新和产业创新深度融合”。
在这一条中,相当部分的内容强调企业在科技创新中的重要地位,如要求“强化企业科技创新主体地位,推动创新资源向企业集聚,支持企业牵头组建创新联合体、更多承担国家科技攻关任务,鼓励企业加大基础研究投入,促进创新链产业链资金链人才链深度融合”等。
对长期从事科技创新研究的学者来说,这些表述特别引人注目,需要高度重视。因为在科技创新相关文件和规划中,我国一直强调以企业为主体、市场为导向、产学研相结合。可以说,产业创新和企业主体地位,原本就是国家科技创新体系题中应有之义,为何《建议》要在科技创新之外特别强调产业创新并将之与科技创新并列?为何要以较大篇幅论述企业在创新中的重要地位并要求创新资源向企业聚集?
这是因为,数智化时代的创新特点,使得产业科技创新实力快速增强,企业创新主体地位极大提升。下面分两个部分对此进行讨论。
数据和AI成为创新重要源泉
伴随数智技术的发展,现实世界的社会行为、经济形态和企业场景都在数字空间产生映射,数据采集主体日益多元,采集途径不断扩展,采集成本显著降低,采集类型也趋于丰富多样,科研数据来源从科学界扩展至社会运行、产业生产、个人生活等全方位全领域,数据融合的规模与范围日益增加。
大型数字平台伴随产业活动同步产生各类运营数据,消费者的行为数据自动产生且时时更新;移动互联网的普及使得大量用户数据和行为数据成为新的科研数据来源,例如医学研究人员使用社交媒体数据更好了解患者心理状况;物联网的发展使得科研人员可以远程实时监测各种传感器数据,例如生态学家可以实时监测动物迁徙情况;科学表征技术的发展为研究者提供大量高精度、高分辨率实验数据,例如扫描透射电子显微镜、冷冻电镜;大型科学装置可以获取极深极广的海量数据。
此外,数据基础设施的开放共享,为基础研究和学科前沿创新提供了科学数据支撑和服务。截至2024年年底,国家地球系统科学数据中心已开放共享数据集3.7万余个,数据资源总量达6.48PB(拍字节),为166个国家和地区的重大科研项目/课题提供了数据服务。
更多的数据意味着更多的信息,更多的数据更意味着蕴含更多的潜在关系。算法的本质就是寻找数据之间的关系,深度学习就是学习如何发现数据间存在的各种关联。AlphaFold预测蛋白质结构的本质,是寻求氨基酸之间的相互关系。它的成功表明,只要是可以表示为序列的数据,不管是文字、语音、图像还是蛋白质序列,都可以使用深度学习模型Transformer捕捉上下文关系。因此,海量数据的意义在于可以通过算法找出更多的数据关系。
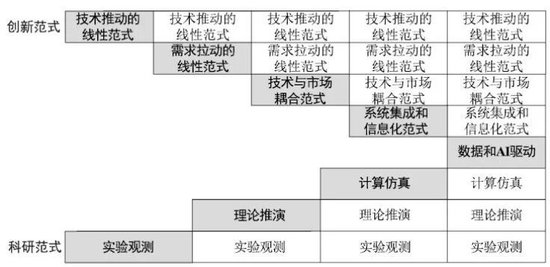
数据和AI重新定义了创新范式。长期以来,我们既有科研范式,也有创新范式。科研范式跨越实验观测、理论推演、计算仿真阶段,正进入“数据和AI驱动”的第四范式。创新范式依次经历技术推动、需求拉动、技术与市场耦合以及系统集成和信息化阶段,进入“数据密集型创新”。
无论科研范式还是创新范式,范式的演进并不是依次替代的关系,而是不断叠加、不断超越、不断融合的进程,它们原本各自演进,但是现在两者正在逐渐趋向同一个方向——“数据和AI驱动”。
其重要的原因是,无论科学问题还是创新问题,最终在很大程度上都可以还原成数据驱动问题。当然,数据和AI驱动的创新并不是替代其他类型的创新范式,而是继起和并存的关系,如图1所示。
图1 科研范式和创新范式的演进
数据和AI驱动的创新,一个重要特征是解决复杂的科学问题。各个领域可获取数据的种类和数量都有显著提升,为复杂问题的解决提供了数据和算法基础。
以往气象学主要依赖局部的气象站点观测数据,随着卫星和气象传感技术的发展,科学家能够收集更广泛的大气层数据、海温数据、云层覆盖数据等,运用计算机更准确模拟地球气候系统。
在药物研发领域,传统药物研发一般遵循“经验+实验”模式,往往耗时数年甚至数十年,耗费巨大,成功率却相对较低。药物研发的漫漫征途始于靶点发现,自20世纪60年代以来,通常采用基于亲和力的生化实验、比较分析以及化学/遗传筛选等实验手段进行靶点识别,虽然实验技术和组学技术不断创新,但真正能够转化为临床治疗的药物靶点却寥寥无几。据相关统计,截至2022年,人类已成功识别的药物靶点尚不足500个,而临床试验中高达80%的失败率更是凸显了靶点发现环节的艰难险阻。
随着生物医学数据的爆炸式增长,药物研发逐步转向“数据+建模”模式。研究人员利用AI处理和分析海量复杂的生物医学数据,挖掘隐藏的模式和关系,预测现有药物或化合物的生物靶点,还能在短时间内识别针对特定疾病的全新治疗靶点。
例如,英矽智能公司利用深度学习模型等AI模型,基于多组学数据和文本挖掘,在特发性肺纤维化小分子药物研究中,成功筛选出20个潜在治疗靶点,并最终筛选出纤维化和衰老双效靶点TNIK,这一发现过程仅耗费1周时间,花费约5万美元,而传统模式下发现靶点需要1年多的时间,花费超过9400万美元。英矽智能公司还利用AI分析200万份肿瘤患者的基因数据,发现卵巢癌的新靶点“CDK12突变”,这一过程仅用了6个月,传统方法需要三四年。
此外,还可以通过大语言模型,对海量医学文献数据进行预训练,快速链接疾病、基因和生物工程,为靶点发现提供有力支撑。纽约干细胞基金会和谷歌研究院合作开发的高通量细胞表型分析平台基于48TB(太字节)的帕金森病患者的细胞图像数据集训练人工智能模型,能够区分不同疾病亚型的细胞图像。
2020年,鄂维南和其学生组成的“深度势能”团队,利用机器学习与物理建模相结合的方法(DeePMD)成功将分子动力学体系模拟规模从100万个原子提升至1亿个,时间从60年缩短至1天,并获得了当年的国际高性能计算应用领域的最高奖戈登·贝尔奖。
不同类型和不同领域的数据交互也有重要意义。创新是一个交互过程,需要不同组织、不同环节之间的信息交互。具有异质性能力的个体和组织间进行多维信息交互,能够提高交流效率和协同解决问题的能力,也让彼此融合多元外界知识和经验,促进新知识的创造。
数据交互形成的多元“数据关系”成为组织内部或跨越组织边界协作创新的内核,不仅带来知识、技能和资源的互动,而且带来基于数据关系的“组织关系”的不断建构与演进。
多维信息交互,能够提升交流效率和获得多元外界知识与经验的能力。数据交互可以避免创新主体对自身的路径依赖,吸收外界信息,实现内外部数据的交叉融合,增强数据挖掘能力。
例如,银行通过与供应链企业合作,实现全链条交易数据的交互,有效进行风险防控,优质客户识别,创新金融服务。伴随数据交互,数据主体之间能够进行更加紧密的联系,增强协同创新。
数据和AI驱动的创新在社会科学研究中同样重要。例如当代经济学的一个重要研究类型是实证研究,即以数据为基础推断变量之间的因果关系。与创新相关的经济金融活动是一个动态复杂系统,但受到数据数量和质量、因果关系可解释性要求和计算能力等因素影响,过往创新相关实证研究的数据量较小,并且采用确认因果关系或某种因素影响程度的处理方法(如主因素分析、双重差分、断点回归等)。
然而,创新过程是科学、技术、企业、产业和制度的动态复杂系统,小样本数据量和少数测量维度难以真实描述创新的本质,在大尺度一般规律和微尺度具体创新场景处理上都显得“数不从心”。
进入数据驱动创新时代,数据规模和实时性、数据深度和广度、数据交互和数据共享能力等均有极大提升,算法和算力也极大改进,有可能揭示高度复杂的创新关系,发现数据间隐藏的复杂关联,助力人们更好理解创新范式的一般规律。
近些年,我国经济政策特别强调解决“信心和预期”问题,这涉及心理、意识、情绪等因素的感知和互动关系判断,在以往经济社会问题研究中,上述因素是一类重要却难以定量加以研究的问题,创新的本质是一种长期风险投资,预期和心理等因素的影响更加明显。
如今,对多模态数据特别是文本数据的处理能力,提供了许多与创新投资相关的情绪和预期等实时信息,支持对数字时代创新范式进行更接近“真实过程”的分析研究。
随着人工智能被更加广泛深度地应用于创新研究,越来越多的学者指出人工智能驱动范式正在脱离数据范式,逐渐成为独立的第五范式。人工智能驱动的创新在缩短研究周期、提高科研效率、发现潜在规律等方面展现出巨大的潜力。
一是数据处理能力跃升。当前,人工智能尤其是大模型能处理高维、异构、海量的科学数据,从粒子对撞机每秒产生的PB级数据,到基因测序的碱基对序列,拓展人类对复杂数据的处理能力。
二是实时校正科研方向。科研人员可以将数据驱动和理论模型驱动方法相结合,更好地提出科学假设,优化实验设计,高效地开展大规模、高通量并行模拟实验,实现过程性微调而无须失败后调整。
三是高效数据关系挖掘能力。以深度学习为例,其能够从数据中自动提取多层次的抽象表示,高效捕捉数据的内在关联与空间分布规律,从而实现对未知数据的准确预测与生成。例如,麻省理工学院的詹姆斯·柯林斯团队应用深度学习算法进行抗生素分子筛选,在数天内从超过1亿个分子中成功识别出一种新型广谱抗生素分子。
四是学科交叉融合特征凸显。科学的各个领域正以前所未有的速度相互交织和交叉。最为明显的例子莫过于2024年诺贝尔物理学奖颁给了两名机器学习领域的元老级人物约翰·霍普菲尔德和杰弗里·辛顿,化学奖则颁给了AlphaFold的发明者——DeepMind公司的德米斯·哈萨比斯和约翰·江珀,以及华盛顿大学的戴维·贝克。这更向人们展示出基础科学的深刻洞见与计算机科学创新“碰撞”可以产生巨大的能量。
产业在科技创新全链条中
的地位更加突出
在数据和AI驱动的创新范式下,产业的作用是此前不可比拟的。过去多年,我们讲“三段论”:科学家做原始创新,技术研发机构开发前沿技术,产业做技术转化。现在,产业重要性全链条提升,与此前主要在技术产业化转换阶段发挥作用相比,已有本质不同。
数据和AI支撑企业从事基础研究
数字领域基础研究往往需要巨大的数据、算力和算法的投入,大型科技企业不仅在海量数据、算力、数据交互和共享等方面具备优势,还能够感知本领域发展所需的基础研究,并且拥有雄厚财力以及事业发展平台,足以吸引大批顶尖人才,从而以算力、算法和数据的最佳组合推动探索“从0到1”的原始创新。
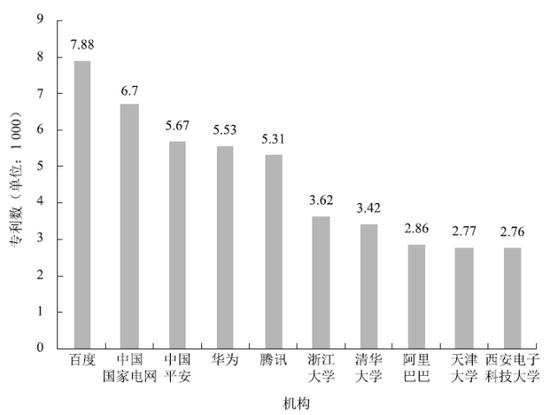
在人工智能国际顶刊的文章发表数量上,2011年全球范围企业发表超过高校,2016年起中国企业的文章发表也超过了高校。在自动驾驶、渲染引擎、虚拟现实、云计算等前沿数字技术领域,从相关专利数量看,国际发明专利排名前20位的均为企业,国内发明专利企业占比超80%(见图2),明显高出一些典型的传统领域,如燃油发动机企业占比为61.89%、燃气轮机企业占比66.24%。
我国某数字企业成为全球最大的区块链专利申请者,即使在量子计算这类基础数字技术领域,企业发明专利数量也远超高校和传统科研机构。国际发明专利排名前20的机构中(截至2022年4月),企业13家,高校2家,科研院所1家,其他4家。从国内发明专利集中度看,排名前三的大型数字企业占比约15%,而在燃油发动机这类传统技术领域,排名前三的机构占比仅为6%左右。
2019年图灵奖被授予皮克斯动画工作室两位联合创始人帕特里克·汉拉恩和埃德温·卡特姆,以表彰他们对3D计算机图形学的贡献。其中,卡特姆是一位基础科学家,在担任计算机教授期间创办企业,这显示出数字时代基础研究成果与产业应用之间的无缝对接。
2012年,华为成立诺亚方舟实验室,之后该实验室研发出神经应答机,并发布基于深度学习的对话生成模型。2015年,腾讯成立智能计算与搜索实验室,主要面向机器学习、视觉技术、语音、自然语言处理等四大方向前沿技术。
2017年,阿里巴巴成立达摩院,从事包括机器学习等领域的研究工作,该研究院于2018年研发出一款可以做图像视频分析和AI机器推理运算的神经网络芯片Ali-NPU,并于2020年发布全球首个自动驾驶“混合式仿真测试平台”,在人工智能领域发表1000多篇论文。
2024年,阿里云凭借原生数据库PolarDB的优异性能,获得国际人工智能领域顶会ICDE(国际数据工程大会)工业赛道最佳论文。图2以自然语言处理这种基础研究领域为例,展示了2020-2021年我国相关专利排名前五的企业均为大型企业。
图2 2021-2022年中国自然语言处理公开专利数TOP10
数据和AI支撑企业进行前沿技术开发
海量数据和AI时代,规模报酬出现了本质变化。规模报酬递增的特点由“边际增量”改变为“新能力涌现”。
规模化法则的基本原理是,随着模型规模的增加,模型的性能也会提高。这一发现激励着研究者们投入更多资源构建更大规模的模型,以期获得更好的性能响应。对这个法则的未来适用边界,研究者有不同看法,但对这个法则在当前阶段的适用性大都赞同。
“规模涌现”规则的意思是,头部企业具有巨量链接和海量数据获取、处理与迭代能力,同时拥有算力方面的优势,当规模超过一个阈值后,就会涌现出后来者无法企及的全新能力,包括深度泛在的感知能力、对多元变量关系的洞察能力、对高度复杂问题的预测能力等,为企业带来强大创新能力。
平台的上述创新优势又会对高端人才和投资者形成强吸引力,因而成为数字前沿技术的重要创新力量。以大模型技术为例,大模型的训练和调整需要极其巨大的数据、算力和算法的投入,这进一步放大了产业界的优势。
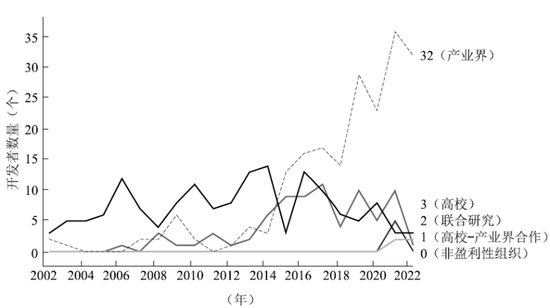
《2023年人工智能指数报告》显示,2002-2014年,学术界在开发最先进的AI系统方面处于领先地位。2014年后,由于尖端人工智能研究需要大量的数据和计算资源,这使得只有少数大型科技企业具备开发和应用大模型的能力,由此前沿大模型的主要开发者,从2014年前以高校为主,转变为以产业界为主。2022年,平台一骑绝尘主导AI大模型创新,和学界、非营利性组织以及各类联合研究的差距越来越大,如图3所示。
图3 2002-2022年分类计算的前沿大模型开发者数量趋势
企业创新成果服务海量客户无须“转化”
大型数字平台连接上亿消费者和百万级或千万级生产者,时时生产和汇聚海量数据,而且能够通过先进的数据采集、感知技术获得深度、广度足够的数据,在强大的算力和算法支持下,准确感知市场需求及变化趋势。
同时,研发结果可以直接应用于海量用户,用户使用反馈也能快速传递给研发团队,持续的数据交互使研发方向能够根据环境变化进行灵活调整,更好优化相关服务。
2025年,抖音日活用户超过8亿,其核心推荐算法有几百亿的原始特征和几十亿的向量特征,推荐系统不仅基于海量内容数据,还通过捕捉用户行为数据、场景数据进行实时反馈和优化,快速更新用户标签,提升个性化推荐效果。
天猫平台利用大数据优势,为“天猫小黑盒”提供趋势洞察、全域仿真、实验场景设计等服务,使得日用品创新周期平均缩短24天。
数据和AI交互形成研发簇群,覆盖场景化技术体系
数字时代,平台往往是大场景运作、跨产业运营、多领域并行推进,集成整合的技术、产品和服务类型众多,能够增强各创新主体之间的场景化数据交互能力,极大促进创新。
截至2021年年底,某数字平台已孕育出15个行业生态,链接企业近88万家,聚集3亿以上用户,390多万家生态资源。头部企业还能带动产业生态圈内大批小企业进入数字时代,逐步形成大企业攻关和开放底层核心技术、小企业调用平台能力的应用创新生态。
百度的Apollo平台形成包含芯片、传感器、人工智能、OEM(定牌生产)、教育、平台服务等的自动驾驶创新网络。在芯片方面,百度成立昆仑芯公司,2020年实现昆仑芯1代AI芯片量产,2022年昆仑芯2代在百度无人驾驶系统实现大规模部署和落地。
企业依托数据获得新创项目投资洞察力
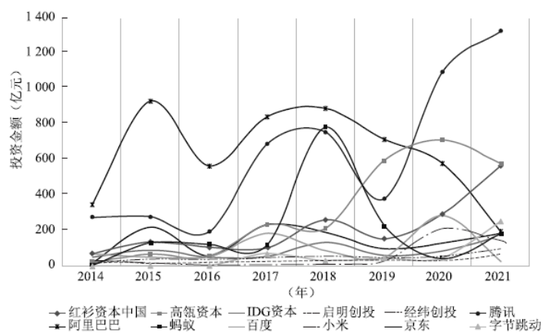
平台企业具有独特的数据优势,能够保持对未来创新方向的高度敏感,同时具有较强的投资能力。近几年,我国新创企业高度集中在数字与智能领域,这既是新创企业自身对科技发展方向的把握,也是创投企业在数智领域集聚投资的引领结果。各类数字企业也渐成长为独角兽企业A轮和B轮投资的半壁江山以及C轮以后的重要力量(见图4)。
此外,大型数字企业因其强大的资源整合、系统管理、资金积累能力,能迅速裂变孵化其他创新企业。据不完全统计,2021年中国独角兽榜单中(共301家),有49家独角兽由母公司孵化。和传统创投资金财务投资特征明显的情形相比,数字企业创投资金具有更明显的战略投资者特征,更偏向于耐心资本、长期主义,重要性不断增加。
图4 2014-2021年平台企业创业投资情况
总之,在数智化时代,企业走在了创新前沿,深度融入了创新全链条,并以大量投资支撑自身前沿技术创新,产业在创新中的地位显著增强。加快推进科技创新,需要进一步提升企业在国家创新体系中的地位,在立项、人才、投入等方面给予更多支持,促进科技创新与产业创新深度融合,更高效建设创新型国家。
来源:财经ThinkTank
(本文作者介绍:教授、研究员、博导、国务院副秘书长、全国政协委员)
